���ɸ�,³���dz�ҵ����̳,����Ʒ��¼�ϼ�
����ժ Ҫ�����Ż�������չ���������ݱ�ը��ʹ��Web��־��������ҲԽ��Խ����δӺ�����Web��־���ھ��м�ֵ����Ϣ��Ϊ��Ŀǰ�о����ȵ㡣��������˻���Hadoop��Ⱥ��ܶ�Web��־�����ھ�ʵ�����������ü�Ⱥϵͳ�ȿ��Դ���������web��־��ͬʱҲ�ܹ��ھ���м�ֵ����Ϣ����֤ʵ������sqoop��Hive�ֿ�ʹ�ͳ���ݿ�֮������Ǩ�ƵĿ����ԡ�
�����ؼ��֣�Web��־;Hadoop;Sqoop;Hive;����Ǩ��
����1 ����
�����������Ŀ��ٷ�չ��ʹ��Web��־���ݳ��ֳ���ըʽ����������Щ������Web�������̺��˴�������Ϣ����Щ��Ϣ����ҵ������һ�ʾ�IJƸ�����ҵ�ķ�չ��Ҫ��Щ�����ṩ���õ�ս�Ծ���֧�֣���˶���Щ���ݾ��м�����ھ�����;��ʹ�ôӺ�����Web�������ھ����õ���Ϣ��Ϊ��Ŀǰ�о����ȵ㣬ͬʱ���ģ�ļ���������ΪWeb�����ھ����ܷ���Чʵ�ֵ��ⲿ����[1]��
������Ժ������ݴ������ֵļ������⣬��Hadoop[2]Ϊ�������¼����õ��˹�����Ƽ������ߵļ����ע;Hadoopƽ̨�������������ʵ����“���㿿���洢”��˼��[3]����˼��ʡȥ�˺����������紫�����һ�����������������ݴ���ʱ�䣬ͬʱ�䲢�л������ݴ�����ʽ�dz������ڴ����������ݡ�
�������Hadoop�ֲ�ʽ�����������ݵ����ƣ�������һЩѧ�߷�Hadoopƽ̨����������о�������[4]����Hadoopƽ̨��ʵ���˶�Web���ݵIJ��л�������������������д���ʱ��;����[5]ͨ������Hadoopƽ̨�������һ�����ڴ�������������־�ķ���ƽ̨;����[1�� 6]����Hadoopƽ̨������Web��־�ھ�ʵ�飬��֤ʵ��Hadoopƽ̨�Ŀ����ԡ�
�������Ļ���Hadoopƽ̨���ȶ�Web��־������������ϴ�����������ھ�ľ�����Ҫ���������ࡢ�쳣�������ھ�Ŀ���ص���Ϣ��Ȼ��ͨ��HIVE���ݲֿ�����û���Ϊ�Ĺؼ�ָ�꣬��Web��־���ݽ����û���Ϊ�ھ�����MySQL�����ھ���չʾ��ͬʱ������sqoop[7]����ڹ�ϵ�����ݿ���ǹ�ϵ�����ݿ����������Ǩ�ơ�
����2 ��ؼ�������
����Hadoop��Apache������������µ�һ���ֲ�ʽ����ƽ̨����Hadoop�ֲ�ʽ�ļ�ϵͳ(Hadoop Distributed File System��HDFS)��MapReduce[8](Google MapReduce�Ŀ�Դʵ��)Ϊ���ĵ�HadoopΪ�û��ṩ��ϵͳ�ײ�ϸ�����ķֲ�ʽ�����ܹ�[2]��
��������Hadoop���ļ�ϵͳHDFS���и��ݴ��Ե��ص㣬��������Ʋ����ڵ�����Ӳ���ϣ�ͬʱ������ͨ���ṩ��������������Ӧ�ó�������ݡ�
����MapReduce��һ�ֱ��ģ�ͣ����ڴ��ģ���ݼ��IJ������㣬����Ҫ�Զ����ݽ���ӳ��(Map)������(Reduce)��ʵ�ּ��㣬��MapReduce��ִ��ʱ��ָ��һ��Map(ӳ��)�������������ֵ��ӳ���һ���µļ�ֵ�ԣ�����һ��������Reduce��Reduce����ͬKey�µ�����value���д������������ֵ����Ϊ���յĽ����
����Hive[9]��һ������Hadoop�ļ�ϵͳ֮�ϵ����ݲֿ�ܹ�����Ϊ���ݲֿ�Ĺ����ṩ������ܣ�����ETL(��ȡ��ת���ͼ���)���ߡ����ݴ洢�����ʹ������ݼ��IJ�ѯ�ͷ�������;ͬʱHive��������SQL�����ԨDHive QL��
����HBase��һ��NoSQL�洢���ݿ⣬�������������������д���ģ���ݣ���һ���߿ɿ��ԡ������ܡ������С��������ķֲ�ʽ�洢ϵͳ������HBase�����������ۻ����ϴ����ģ�ṹ���洢��Ⱥ[10]��HBase����HDFS��Ϊ���ļ��洢ϵͳ������MapReduce������HBase�еĺ������ݣ�����Zookeeper��ΪЭ�����ߡ�
����Zookeeper��Google��Chubbyһ����Դ��ʵ�֣���һ��Ϊ�ֲ�ʽӦ������ƵĿ�ԴЭ������������һ����ԭ�O���ֲ�ʽӦ�ó�����Ի�����ʵ��ͬ����������ά�������������;�û�����ʹ��Zookeeper�ṩ�Ľӿڷ����ʵ��һ���ԡ��������leaderѡ�ټ�ijЩЭ�飬ͬʱZookeeper��������Ϊ�����ṩ����ͬʱҲ֧�ֶ����ɼ�Ⱥ���ṩ����
����Sqoop[7]��“SQL to Hadoop”����д����һ��������Hadoopϵͳ�ͽṹ�����ݴ洢ϵͳ��������ݽ��������������������ڽ���ͳ���ݿ�(��MySQL��Oracle)�е����ݵ���HDFS��MapReduce�����Hive����ʹ�ã���֧�ֽ�������Ľ�����ݵ�������ͳ��ϵ�����ݿ���[11]��
����3�û���Ϊ�ھ�Ĺؼ�ָ�����
���������PV��ҳ���������ΪPV(Page View)����ָ�����û��ڸ���վ���ҳ����ܺͣ�һ�������û�ÿ��һ��ҳ��ͱ���¼1��;������վ����������������Ϊ�����û�������վ����Ȥ��ͬʱ������վ��Ӫ����˵������Ҫ������վÿ����Ŀ�µ��������
����ע���û�����ÿһ����վ��ע����û�����;��Ӫ��ͨ����ע���û����������Բ鿴����վ�ƹ�״����
����IP����һ��֮�ڣ�������վ�IJ�ͬ�Ķ���IP �����ܺ�;����ͬһIP���۷����˼���ҳ�棬����IP ����Ϊ1��
���������ʣ�ֻ�����һ��ҳ����뿪����վ�ķ��ʴ���ռ�ܵķ��ʴ����İٷֱȣ���ֻ�����һ��ҳ��ķ��ʴ��� / ȫ���ķ��ʴ�������;�������Ƿdz���Ҫ�ķÿ����ָ�꣬����ʾ�˷ÿͶ���վ����Ȥ�̶ȣ���������Խ��˵����������Խ�ã��ÿͶ���վ������Խ����Ȥ����Щ�ÿ�Խ��������վ����Ч�û�����ʵ�û�;��ָ��Ҳ���Ժ�������Ӫ����Ч����ָ���ж��ٷÿͱ�����Ӫ��������������Ʒҳ����վ��֮������ʧ����������
����4�û���Ϊ�ھ��ƽ̨���
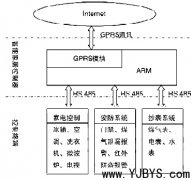
������־�ɼ�ģ�飺������ǰ��web�������е���־���͵���־���սڵ��ϡ�������Բ���ÿ�춨ʱ�Ľ������������е���־���͵����սڵ㡣������־���������ݽ�Сʱ�����սڵ����ͨ��shell����ֱ�ӽ���־�����ϴ���HDFS��;�����־�������dz��࣬��������ʱ����ʹ��flume�������ݴ�����
������־��ϴģ�飺ͨ��Hadoop�ı�̿��MapReduce���ϴ���HDFS��ԭʼ���ݽ�����ϴ;���幤���ɷ�Ϊ�����Σ�Map�κ�Reduce�Ρ��������ηֱ���������������ʾ����Map������Reduce������Map��������һ����ʽ�����룬Ȼ�����ͬ��Ϊ��ʽ���м������Hadoop�Ḻ�����о�����ͬ�м�keyֵ��value���ϵ�һ�ݸ�Reduce������Reduce��������һ������ʽ�����룬Ȼ������value���Ͻ��д�������������Reduce�����Ҳ����ʽ�ġ�