酷妙街,欲盖弥彰造句,胥渡吧是什么
一、企业员工“过劳”现状分析
1.抽样情况
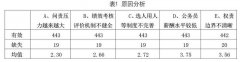
中国适度劳动研究中心通过实证调研,从企业员工职场行为与“过劳”的角度进行研究,采用方便抽样的原则,对全国范围进行抽样调查。样本覆盖全国22个省、直辖市、自治区(内蒙古、黑龙江、福建、贵州、云南、西藏、甘肃、青海、宁夏9个地区未进行抽样)。本次调查共覆盖18个一级分类行业(未涉及卫生和社会工作、国际组织),覆盖率为900%,涉及53个二级分类行业,占二级分类行业总数的5521%;覆盖8类职业中的6大类及25个中类。共发放问卷1500份,回收1359份,回收率906%,其中有效问卷1176份,有效率865%。通过α系数法对该问卷进行内部一致性信度检验,所有题目Cronbach’s α系数为0729,说明该问卷的信度较高。在研究文献和请教专家的基础上,认为此两项内容具有良好的内容效度。通过因子分析得到,KMO统计量为0782,巴特利特球度检验近似卡方值为6560736,且都在0001的水平上具有统计学意义,说明该问卷都具有良好的结构效度。
2.主要调研工具
本研究的主要调研工具为工作疲劳蓄积度量表。借鉴日本厚生劳动省发布的《劳动者的疲劳积蓄度自我诊断调查表》(以下简称自测表),该量表分为自觉症状的评价(包括13道题目,主要测量劳动者对疲劳的主观感觉),以及工作状况的评价(包括7道题目,主要测量劳动者对工作状况的感觉)两部分。通过计算得出劳动者疲劳积蓄度总分,该分值在0~7分之间,并且该量表认为1分为疲劳积蓄可能性的转折点,即0~1分表示没有疲劳蓄积的可能性,2~7分表示存在疲劳蓄积的可能性[1]。本研究未直接采用疲劳蓄积度的总分来判断过度劳动程度,这是由于0~7分等距间隔分数仅有1分,很难区分相邻两个分数所反映的疲劳蓄积实际差异的大小。由于已有日本学者及国内学者对该量表最后的总分进行了严格地划分,并用该量表测得的疲劳蓄积度的结果来表示“过劳”程度[2]。因此,本研究也将0~7分划分成四个分数区间,即0~1分表示“过劳”,2~3分表示轻度“过劳”,4~5分表示中度“过劳”,6~7分表示重度“过劳”,划分方法与国内外学者的研究一致。笔者认为,通过将总分划分为四个分数区间来反映“过劳”是严谨、合理的。将这四个分数段分别进行赋值,1=没有“过劳”、2=轻度“过劳”、3=中度“过劳”、4=重度“过劳”,数值越高表示企业员工“过劳”程度越严重,该变量为顺序变量。
二、企业员工“过劳”的状况分析
1.企业员工“过劳”的总体状况分析
由日本厚生劳动省发布的自测表计算出企业员工“过劳”状况,总分0~7分,0分有330人,占281%,1分有156人,占133%,2分有170人,占145%,3分有108人,占92%,4分有166人,占141%,5分有91人,占77%,6分有71人,占60%,得分均值为251±260分,中位数为2分,说明从总体上看企业员工“过劳”程度较低。其中,没有“过劳”的人员数为486人,占413%,轻度“过劳”的人员数为278人,占236%,中度“过劳”的人员数为257人,占219%,重度“过劳”的人员数为155人,占132%。人员较为集中地分布在没有“过劳”的区域,但轻度和中度“过劳”人员所占比例均超过20%,轻度“过劳”和重度“过劳”人员之和所占比例为455%,而总体来看“过劳”人员比例已达到587%,接近2/3的企业员工存在“过劳”现象,且主要为轻、中度“过劳”。
2.人口统计特征下的企业员工“过劳”状况分析
(1)从企业员工性别角度来看,男性“过劳”总分均值为280,女性为221,两个独立样本T检验结果t值=451,企业男性员工与女性员工在“过劳”程度上呈显著差异(P<0001),男性分数均值明显高于女性。男性没有“过劳”的人员组内所占百分比为364%,而女性该比例为465%,明显高于男性,而处在中度、重度“过劳”的男性员工组内百分比为404%,而女性该比例仅为295%,明显低于男性。所以呈现出男性中、重度“过劳”所占比例明显高于女性的现象。
(2)从企业员工年龄分布情况来看,企业员工平均年龄为2882±559岁,中位数为28岁,其中25岁及以下人员占303%,26~35岁人员占600%,36~45岁人员占73%,46~55岁人员占23%,本次抽样没有涉及55岁以上人员。方差分析结果F值=3898,不同年龄段的员工“过劳”程度呈显著差异(P=0009),表现为25岁及以下人员“过劳”程度较低,且没有“过劳”的人数较多;26~45岁人员“过劳”程度明显高于其他年龄段人员,且轻、重度比例明显高于其他人员,46~55岁人员“过劳”程度介于中间位置,主要集中在没有“过劳”和中度“过劳”两个区域。
(3)从企业员工受教育程度来看,初中及以下者5人,占04%,中专、职高、技校者19人,占16%,普通高中者11人,占09%,大专者131人,占113%,本科者669人,占575%,硕士及以上者328人,占282%,说明调查群体以大学生、研究生为主体,受教育水平较高。方差分析结果F值=4173,企业中不同文化程度的员工在“过劳”程度上呈显著差异(P=0016),且表现出大学及以上学历者“过劳”程度明显高于其他人员,主要集中在轻度和重度“过劳”两个区域。
三、企业员工“过劳”成因的“推-拉”理论模型的构建
1.主要研究变量
(1)因变量。本研究主要基于行为和结果的角度,将“过劳”广泛定义为过度劳动而导致的疲劳蓄积,这里既强调了“过劳”是一种劳动行为,又强调了该种行为所引发的结果。2004年日本厚生劳动省发布了自测表,本研究就是在该量表的基础上,选择“过劳”程度作为因变量并进行量化处理,从而能够进一步研究企业员工“过劳”的成因。
(2)自变量。本研究共涉及27个自变量,在问卷中所对应的题目共28道,其中26道题目都采用的是李克特五点量表法,且均为“非常不符合”、“比较不符合”、“一般”、“比较符合”、“非常符合”这五个选项,在数据处理时由1~5进行赋值,因而这26个自变量均为顺序变量。其余2道题分别为月均工资收入和月均生活支出,结合这两道题的特点,采用支出与收入比来反映企业员工的经济压力,因而该变量为数值变量。为使统计结果清晰化,将这些自变量逐一进行编码。
“推-拉”理论是人口学的经典理论,该理论认为人口迁移是促进和阻碍两种不同方向的力的作用结果,即“推力”和“拉力”。本研究所指的“推力”和“拉力”并非经典人口迁移理论中的“推力”和“拉力”,只是借用这两个词汇,从而便于对影响因素进行归纳总结、分组论证以及对结果的形象阐释。本研究在国内外文献研究的基础上,将影响企业员工疲劳积蓄度的27个自变量划分成3组因素,即“外推力”因素、“内拉力”因素和“减缓”因素,具体如下。①“外推力”因素:该组因素是指这些因素来自于劳动者的非自身因素,是劳动者在企业组织管理需要的推动下或者为了满足自身较低层次的需求,被动延长劳动时间、增加劳动强度等被动接受过度劳动的要求而出现过度劳动现象的诱因。该组因素包括15个自变量,即a1=工作量、a2=资源限制、a3=岗位职责、a4=工作重要性、b1=考核标准、b2=企业加班文化、b3=职场民主、b4=薪酬体系、b5=管理效率、b6=
技术变革、b7=管理监督、c1=工作能力、c2=竞争压力、c3=生存压力、c4=经济压力。②“内拉力”因素:该组因素是指劳动者在自身内在因素的促使下或者为了追求更高层次的需求,愿意并主动延长劳动时间、增加劳动强度等主动接受过度劳动的要求而出现过度劳动现象的诱因。该组因素
包括8个自变量,即:d1=工作兴趣、d2=拼搏进取、d3=职业忠诚、d4=完美主义、d5=展现才华、d6=他人肯定、e1=经济追求、f1=职位晋升。③“减缓”因素:该组因素是指劳动者能够缓解自身的疲劳积蓄度,减少因过度劳动对身体、心理健康所带来伤害的原因。该组因素包括4个自变量,即:g1=企业限制加班、g2=体育锻炼、g3=法律意识、g4=养生保健。
2.理论假设
假设1:“外推力”因素对企业员工的“过劳”影响作用显著且具有积极的作用效果,即“外推力”因素表现越突出,企业员工疲劳积蓄度就越高,员工“过劳”程度越大,对企业员工“过劳”具有显著外推力作用。
假设2:“内拉力”因素对企业员工的“过劳”影响作用显著且具有积极的作用效果,即“内拉力”因素表现越突出,企业员工疲劳积蓄度就越高,员工“过劳”程度越大,对企业员工“过劳”具有显著内促力作用。
假设3:“减缓”因素对企业员工的“过劳”影响作用显著且具有消极的作用效果,即“减缓”因素表现越突出,越能够降低企业员工疲劳积蓄度,员工“过劳”程度越能够得到缓解,对企业员工“过劳”具有显著缓解作用。
假设4:“外推力”因素对企业员工“过劳”的作用效果在所有因素中占主导作用。
四、理论模型的验证
1.研究方法
由于因变量是顺序变量,所以使用STATA110中的ologit命令[3]来解决有序响应的问题,该命令是用来考察自变量对因变量选择的概率的影响[4]。本文主要通过ologit回归模型对企业员工过劳的影响因素进行分析。
因变量为五分变量,所以设y表示在{1,2,3,4,5}上所取得值的有序响应,x为解释变量,假定潜变量y*i=xβ+e,其中β表示K*1向量,残差e服从Logistics分布。最终得出模型为:
p(Yi>i)=φ(θi-xβ)=exp(θi-xβ)1+exp(θi-xβ), i=1,2,3,4,5(1)
通过vif命令对回归模型进行多重共线性检验。由于ologit回归模型的回归系数不能反映各自变量对因变量的影响程度的真实大小,只能作为各自变量相互比较、排序的依据,回归系数的符号也无法说明中间选择的影响方向。因此,各自变量对企业员工过劳程度的影响程度和方向需要通过定量的计算得到具体数值,而将各自变量的影响程度进行比较、计算,必须通过常对数模型,转换成弹性进行分析,即计算出各自变量对因变量的边际贡献。某个自变量对因变量的边际贡献是指在其他变量取均值时,该变量变动1个单位对因变量选择的概率影响。